
What is Cypher?
Cypher란 MY SQL데이터 베이스에서 사용되는 SQL처럼 Neo4j 데이터베이스 쿼리에 사용되는 그래프 쿼리 언어이다.
- return 을 꼭 써주어야함.
- return 을 써주지 않으면 다음과 같은 Syntax Error가 난다.

예제
Match (m:Movie) where m.released > 2000 RETURN m limit 5
결과
2000이후에 발매된 영화 중 결과를 5개로 제한하여 보여준다.

1. 2005년 이후 발매된 영화를 검색하라.
- Match (m:Movie) where m.released > 2005 RETURN m
2. 2005년 이후에 발매된 영화 수를 검색하라.

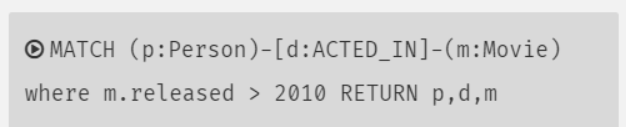
Nodes and Relationships
Nodes와 Relationships은 그래프 데이터베이스의 기본 구성요소이다.
Node
노드는 entitiy를 의미한다. 하나의 노드는 RDB에서 한 행에 해당하는 데이터와 비슷하다.

위 그림엔 Person과 Movie라는 두 개의 노드가 있다. Cypher 쿼리를 작성할 때, 노드는 (p: Person)과 같이 괄호로 묶여 있다. p는 변수이고, Person은 참조하는 노드의 유형/label 이다.
변수명은 n,p,m 등 자유롭게 써도 되는 것 같다.
- MongoDB 처럼 Node는 자유로운 형태를 가질 수 있다.
Relationship
두 개의 노드는 하나의 relationship 으로 연결된다. 위의 이미지에서ACTED_IN, REVIEWED, PRODUCED, WROTE, DIRECTED 과 같은 것이 모두 노드들을 연결하는 relationship들이다.
Cypher 쿼리를 작성할 때, relationships는 [w:WORKS_FOR] 와 깉이 대괄호로 묶여 있다. 여기서 w s는 변수이고, WORKS_FOR 는 참조하는 relationship의 유형이다.
- 두 개의 노드는 둘 이상의 relationship으로 연결 될 수 있다.
예제
MATCH (p:Person)-[d:DIRECTED]-(m:Movie) where m.released > 2010 RETURN p
결과
2010년 이후에 발매된 영화를 감독한 모든 사람, 해당 영화, 관계가 출력된다.

- 비슷한 예제
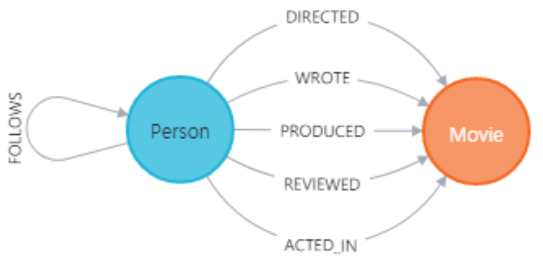
- 2010년 이후에 발매된 영화에서 연기한 사람, 해당 영화, 관계를 출력하라.
- 2010년 이후에 발매된 영화에서 연기한 사람, 해당 영화, 관계를 출력하라.
Labels
Label : 노드 또는 관계의 이름/ 식별자(identifier)
label은 MongoDB에서 Collection과 비슷한 것이다
아래 이미지에서 Movie와 Person은 Node의 Label이고, ACTED_IN, REVIEWED 등은 Relationship의 Label이다.
Cypher 쿼리를 작성할 때, Labels 앞에 ( :Person or :ACTED_IN ) 콜론이 붙는다.
(p:Person)
- p : 변수
- Person : labeled nodes
- Label은 특정 유형의 노드에서만 작업을 수행하려는 경우에 사용된다.
예제 - 비교
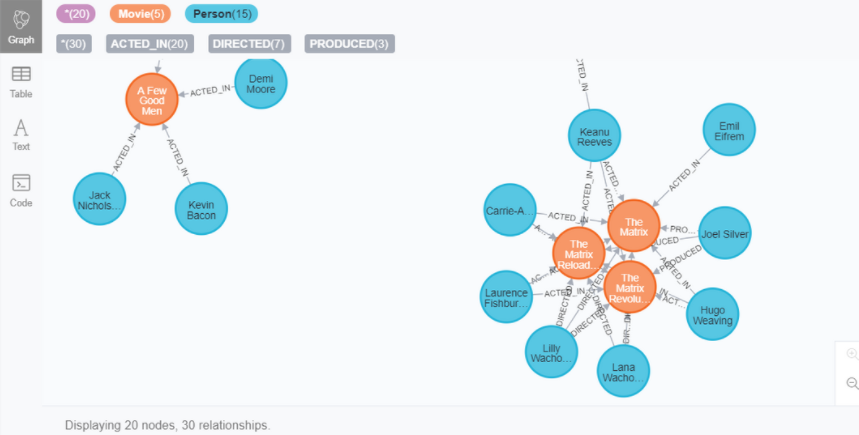
MATCH (p:Person) RETURN p limit 20
위의 명령에선 20개의 person label이 붙은 노드가 리턴되지만, 아래에선 label에 상관없이 20개의 노드가 리턴된다.

MATCH (n) RETURN n limit 20
Properties
속성 : node와 relationship들의 속성을 추가하는데 사용되는 name-value 쌍.
예제
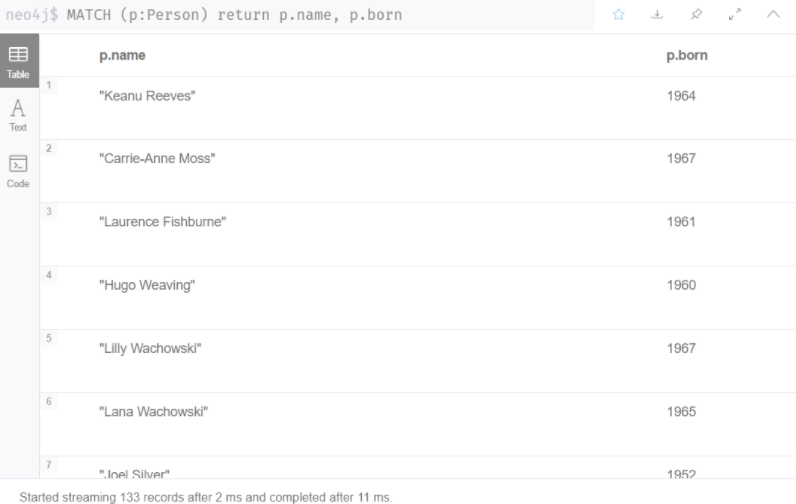
MATCH (m:Movie) return m.title, m.released
결과
Movie 노드를 반환하지만 오직 title과 발매일 속상만 반환된다.
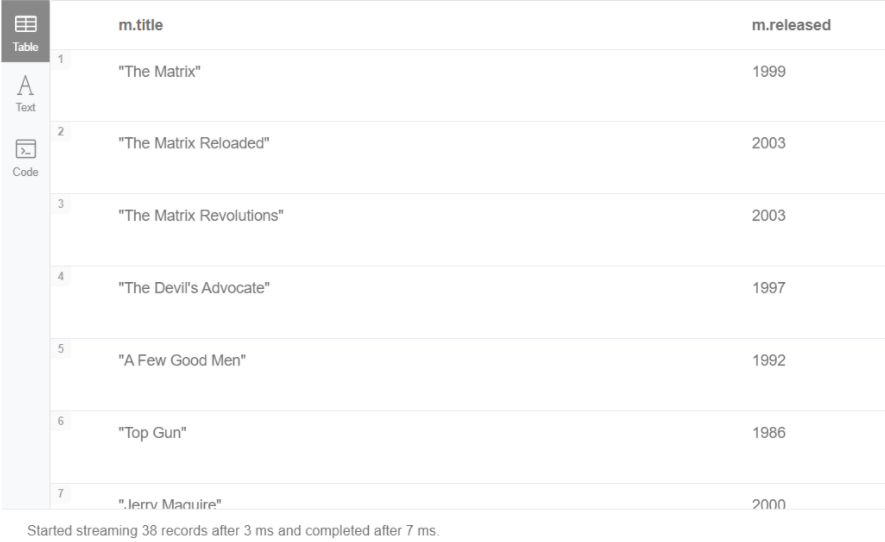
- 다른 예제
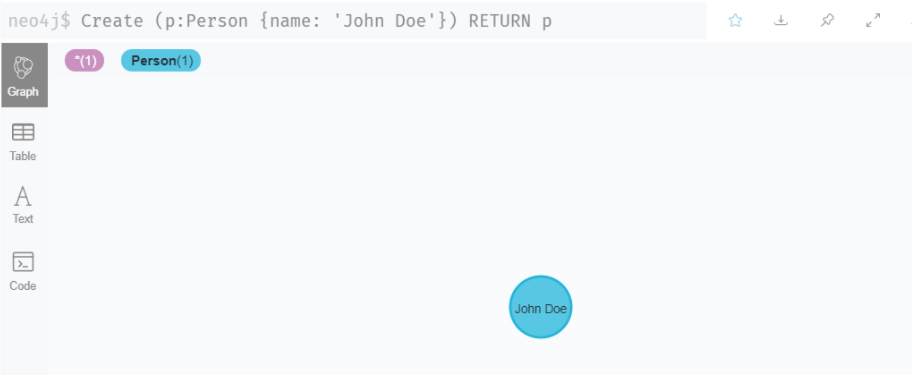
Create a Node
Create (p:Person {name: 'John Doe'}) RETURN p
예제
Finding Nodes with Match and Where Clause
Match 절은 특정 패턴과 일치하는 노드를 찾는데 사용된다. 이것은 Neo4J DB에서 데이터를 가져오는 기본 방법이다. 대부분의 경우, Match는 결과의 범위를 좁히기 위한 특정 조건과 함께 사용된다.
Match (p:Person {name: 'Tom Hanks'}) RETURN p
위의 방식으로 찾으면 문자열 일치 기반으로 필터링을 할 수 있다.
위 아래 쿼리의 결과는 일치하지만, 아래와 같이 Where 절을 사용하면 복잡한 필터링을 사용 할 수 있다.
MATCH (p:Person) where p.name = "Tom Hanks" RETURN p
예제
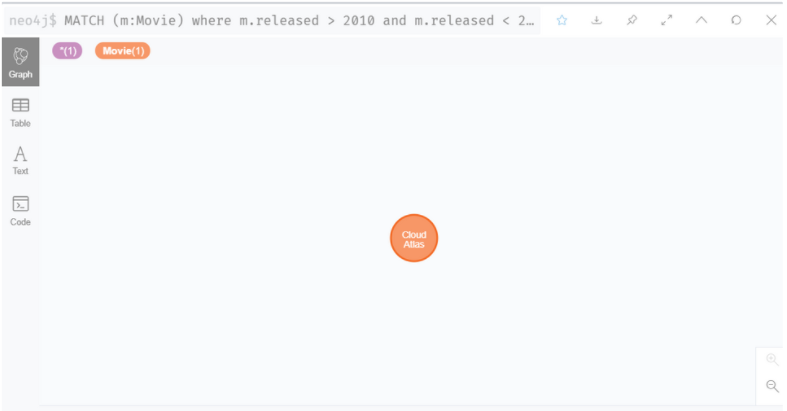
MATCH (m:Movie) where m.released > 2010 and m.released < 2015 RETURN m
결과
: 2010년에서 2015년 사이에 발매된 영화 리턴하라.
Merge Clause
Merge 절은 다음에 사용된다.
- 기존 노드를 MATCH 하거나 그들을 묶을 때
- 새로운 노드를 만들고 그들을 묶을 때
이것은 Match 와 Create 의 조합이다. 데이터가 MATCH되거나 CREATE된 경우 추가 액션을 지정할 수 있게한다.

위의 쿼리는 Person 노드가 존재하지 않을 경우 Person 노드를 생성한다.
노드가 이미 존재하는 경우, lastLoggedInAt 속성을 현재의 타임 스탬프로 설정한다.
노드가 존재하지 않고 대신 새로 생성된 경우 createdAt 속성을 현재 타임스탬프로 지정한다.
예제
Write a query using Merge to create a movie node with title "Greyhound". If the node does not exist then set its released property to 2020 and lastUpdatedAt property to the current time stamp. If the node already exists, then only set lastUpdatedAt to the current time stamp. Return the movie nodereate a Relationship

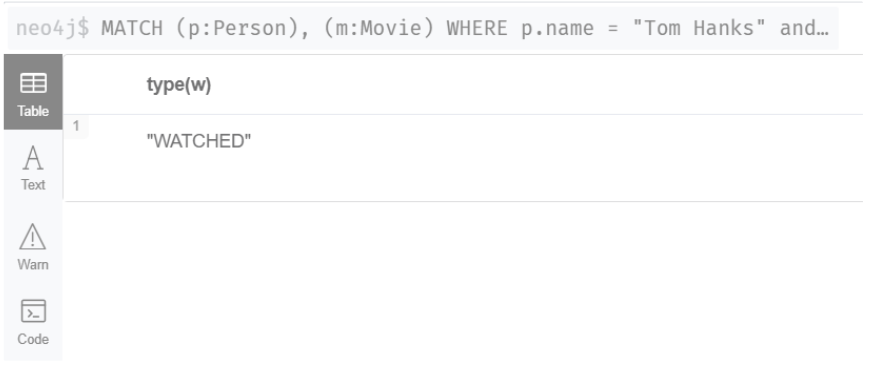
Create a Relationship

결과
위의 명령문은 WATCHED relationship을 만든다. 이름이 Tom Hanks인 사람과 제목이 Cloud Atlas인 영화를 Watch관계로 연결 시킨 후 relation의 타입(i.e WATCHED) 을 리턴시킨다.
Relationship Types
- outgoing: →
- incoming: ←

예제 - 코드 비교
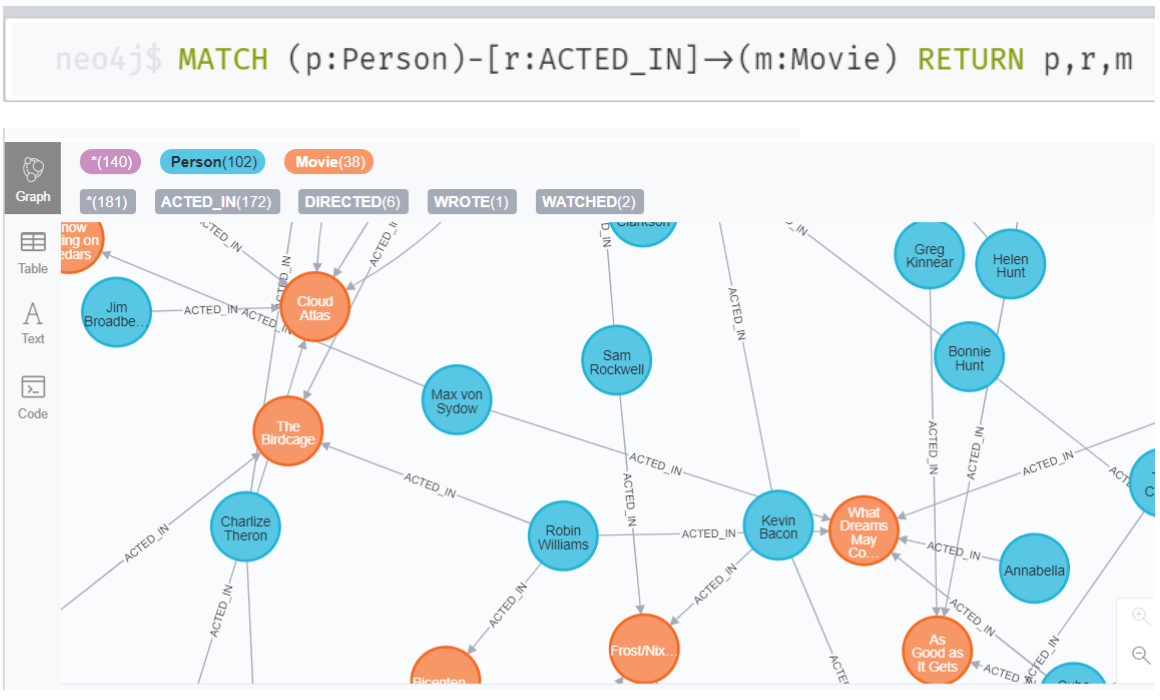
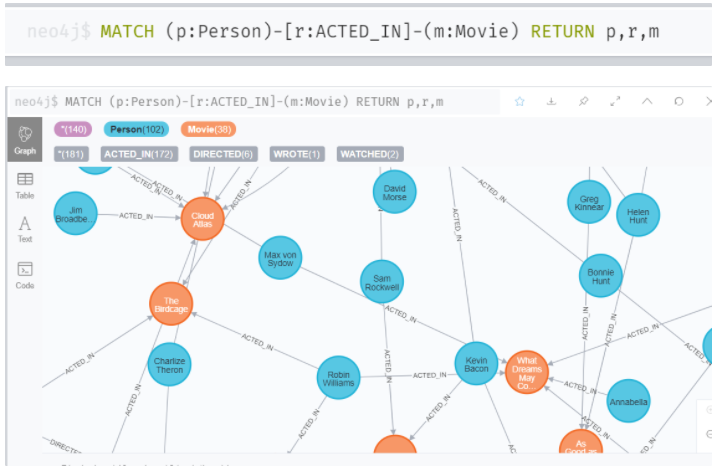
영화 데이터셋은 영화 ← 사람 인 경우가 대부분이라(내 생각) 위 아래의 코드 결과가 같다.
그 외 예제

'공부기록 > Data Engineering' 카테고리의 다른 글
| [PostgreSQL] macOS에 PostgreSQL 설치 및 설정 (2) | 2022.05.01 |
|---|---|
| [ELK] elastic stack 이란 / 개념 / 구성 요소 / 용도 (0) | 2022.04.23 |
| [neo4j] variables 변수 이해하기 (0) | 2021.06.05 |
| [NoSQL] Key Value Model / Redis - (1) 개념 , 장단점 (0) | 2021.04.17 |
| [My SQL] Error Code 1175 해결 방법 (0) | 2020.10.15 |



