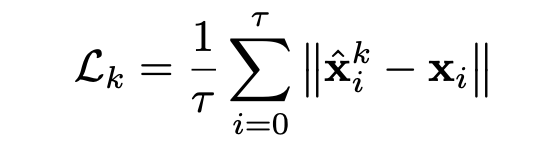[논문요약] SCINet: Time Series is a Special Sequence (2021)
hijyun2023. 4. 11. 22:54
반응형
Introduction
There are mainly three kinds of TSF(Time Series Forecasting) methods using deep neural networks. (i) RNNs (ii) Transformer-based model (iii) TCN (temporal convolutional network) Despite the promising results of TSF methods, they do not consider the speciality of time series. In time series sequence, the temporal relations are largely preserved after downsampling into two sub-sequences.
Motivated by this property, this paper propose a novel neural network architecture named SCINet(sample convolution and interaction network).
The motivation of this paper is...
“ Time series is a special sequence. ”
The main contribution of this paper are …
An effective representation with enhanced predictability by iteratively extracting and exchanging information at multiple temporal resolutions.
Building SCI-Block, which downsamples the input data/feature into two sub-sequences, and then incorporate interactive learning between the two convolutional features within each block after extracting features.
SCINet achieves competitive forecasting accuracy on spatial-temporal TSF tasks.
Related Work and Motivation
One of the popular type of TSF model is the so-called temporal convolutional network, wherein convolutional filters are used to capture local temporal features.
SCINet has several key difference with the TCN model based on dilated casual convolution.
Rethinking Dilated Causal Convolution for Time Series Modeling and Forecasting
SCINet: Sample Convolution and Interaction Network
(영어로 요약하다가 귀찮아서 갑분 한글...) 🤑
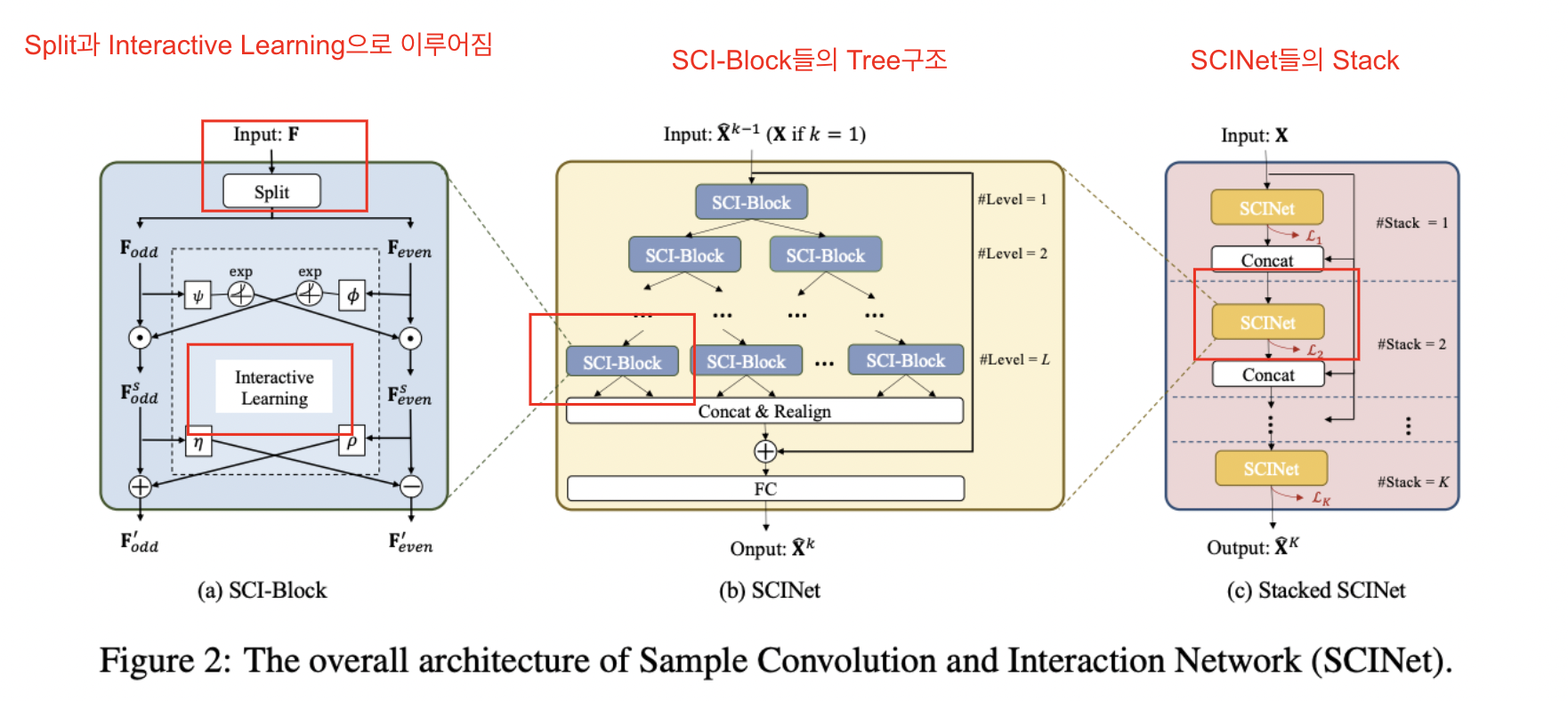
SCINet은 크게 3가지 구조로 이루어져 있다.
stack구조로 쌓여있고, 하나의 SCiNet은 Block들의 트리 구조로 이루어져 있다.
블럭은 크게 스플릿, interactive learning으로 이루어져 있다. 스플릿에선 짝수와 홀수 부분으로 시퀀스를 둔다. Interact는 두가지 시퀀스의 정보를 교환하여 융합시키는 과정을 말한다.
이 블럭들이 트리구조로 반복되어 쌓아지면 SCiNet이 되고, 이 SCINet을 다시한번 스택을 하는 구조를 stacked SCINet이라고 한다. 논문에선 스택을 1-2개 쌓는다.
SCI-Block
블락에서 홀수 파트와 짝수파트로 나눠서 sub sequence로 나눈다.
split을 한 후 학습을 하고 다시 스플릿을 한 후 학습을 하고 스플릿을 한 후 학습을 하는 걸 반복한다.
왜 이렇게 나누는가?
이것의 장점은 무엇일까?
1D-Conv 의 단점은 너무 local 한 정보에 의해서만 학습이 되고 long term 에 대해 학습이 되지 않는 다는 단점이 존재하는데split을 활용하면 더 많은 양의 look back을 하면서 학습이 가능해진다.
Why Split ?
Dilated Conv를 사용하는 효과를 내면서 Dilated Conv의 단점을 보완하기 위해
split을 여러번 할 수록 더욱더 long term에 대한 정보가 반영되어 split을 여러번 할 수록 더 큰 dilated convolution을 사용하는 효과
더 넓은 Long term에 대한 정보 학습이 가능
Why Interactive Learning ?
split된 down sample 간에 parameter를 share하지 않는데 여러 sample에서 시계열의 다양한 특성을 뽑아 Interactive하면 rich한 representation이 가능할 것이라는 아이디어에서 착안
split을 여러번 할 수록 더욱더 long term에 대한 정보가 반영된다.
SCI-Net
SCI-Block을 활용하여 Binary Tree의 구조로 만든 것이 SCINet
추출된 Feature들을 병합하고 정렬한 후 입력 시계열의 Residual Connection을 더해준다.
FC Layer를 통해 시계열의 길이를 T에서 τ로 바꾸어 예측값을 반환
Stacked SCINet
첫번째 scinet에서 나온 예측된 output에 대해 loss를 구하고,
다음 sciNet의 인풋으로 원래 inputx (화살표)를 반복적으로 사용하고 이전 sciNet에서 나온 predict value를 한 번 더 사용한다.
이 과정을 반복 하여.. stack한 수 만큼의 loss가 total loss가된다
total loss
Experiments
결론
SCINet은 시계열의 특성이 뚜렷한 데이터 셋에서는, 불규칙한 시계열에 대해서는 성능을 보장하기 어렵다고 한다.
split을 통해 장기 패턴을 잡아내는 과정이 흥미로웠다.
(2023년 기준) 단변량 Time Series Forecasting 시계열 벤치마크 데이터셋에서 SOTA를 달성한만큼 .. 아이디어를 눈여겨볼만한 것 같다.