시계열 분석을 하면 정상성 검정을 수행한다.
졸업한지 벌써 3년이 지나가는 지금,,,
정상성을 따지는 과정이 너무 익숙하고, 왜 수행했는지? 기억이 희미하다.
이 포스팅에서 시계열 데이터에 대해 알아보고, 시계열 데이터의 정상성에 대해 정리하고자 한다.
What is a time series?
- time series is a set of observations taken sequentially in time.
시간에 종속적으로 측정된 데이터들의 집합을 말한다.
흔히 말하는 시계열이라고 하면 주식! 을 떠올릴 수 있다.
아래 그램에 보이는 일정한 시간에 (예를들면 종가) 관측된 비트코인의 가격이 대표적인 시계열 데이터의 예시이다.

Types of time series
- Regular time series : consist of observations taken at consistent time intervals.
- Irregular time series : consist of observations at irregular intervals of time
시계열 데이터의 타입은 시간 간격이 일정한 데이터와 그렇지 않은 데이터로 나뉜다. 주로, 다뤄지는 데이터는 Regular time series이므로 시계열 데이터라고 하면 일정한 시간 간격으로 측정된 값들의 집합이라고 생각하면 된다. Irregular time series를 다루는 경우는 거의 없으므로 시계열이라고 하면 Regular time series라고 생각하면 된다.
Stationary and non-stationary time series
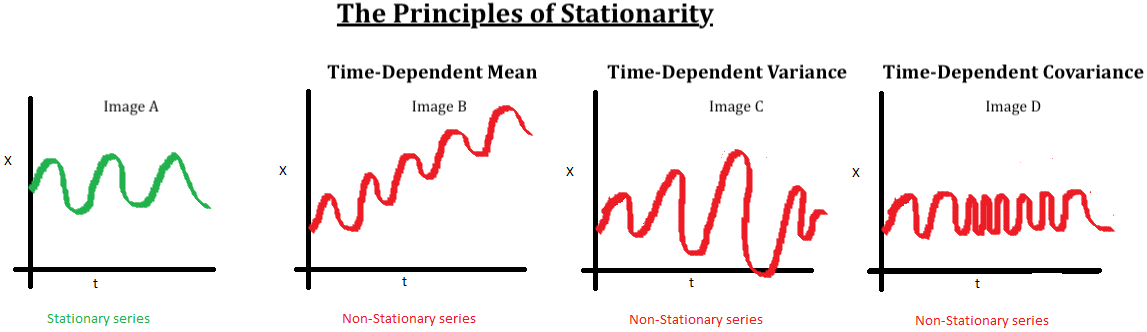
We call a time series stationary when the probability distribution remains the same at every point in time.
A standard Gaussian distribution is defined by two parameters -- the mean the standard deviation.
정상 시계열은
change in mean over time : 시간의 흐름에 따라 평균이 일정해야한다.
change in variance over time : 이분산성(geteroscedasticity)을 가져서는 안된다.
https://assaeunji.github.io/statistics/2021-08-08-stationarity/
다음 중 정상 시계열은? 답은 아래에

분명하게 계절성이 보이는 (d), (h), (i)는 후보가 되지 못합니다. 추세가 있고 수준이 변하는 (a), (c), (e), (f), (i)도 후보가 되지 못합니다. 분산이 증가하는 (i)도 후보가 되지 못합니다. 그러면 (b)와 (g)만 정상성을 나타내는 시계열 후보로 남았습니다.
정상 시계열이란
자료과 관측된 시점과 무관하게 시계열의 특징이 유지되는 시계열을 말한다.
1. 추세나 계절성이 없어야함. 평균 수준이 일정해야함. 시계열의 분산이 일정해야함.
2. 일정한 분산을 갖고 평평한 형태 (이분산성을 가지면 안 됨)
3. 백색 잡음 (white noise) : 정상 시계열. 관찰 시점과 상관없이 램덤
4. 일반적으로는, 정상 시계열은 장기적 예측할 수 있는 패턴을 나타내지 않아야함.
5. 주기가 고정되어있지 않은 순환 성분은 정상시계열로 볼 수 있음

정상성 왜 따지는 걸까?
Ironically, many (if not most) real-world time series are non-stationary.
대부분의 우리가 아는 시계열은 추세가 있거나, 계절성이 있고 비정상적이다.
그런데 왜 통계적 방법론에서는 정상성이 중요한걸까?
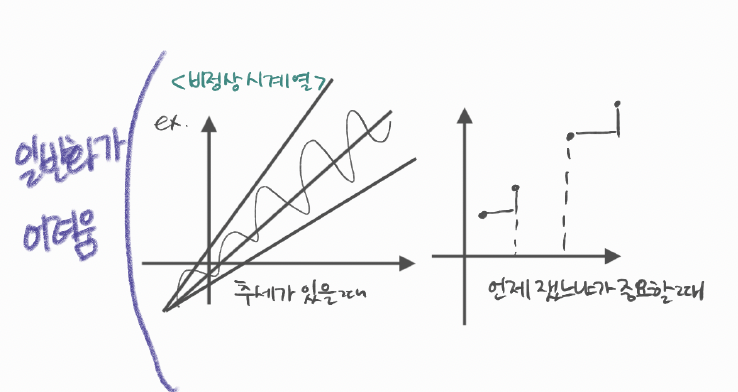
대부분의 '통계적' 시계열 분석 방법론은 시계열 데이터가 일정한 평균과 분산을 가진 확률 과정(Stochastic process)을 따른다고 가정 한다. 만약 데이터가 시점에 따라 분포가 달라진다면 이런 통계적 가정하에 분석된 것들이 의미가 없어진다. 따라서, 회귀 분석을 진행할 때에도 독립성, 선형성, 등분산성, 정규성을 가정 하듯 통계적 시계열 방법론에서는 '정상성'을 가정하는 것이 중요하다.
정리를 하면
통계적 시계열 분석 방법론은 Stochastic process을 따르는 시계열이 있다고 가정하고, Sample을 통해 통계적 과정을 알아내고자 하는데 그 assumption 중 하나가 stationarity이다.
Stationarity 확인하는 방법
정상성을 확인하는 대표적인 방법은 아래 두 가지다.
- 그래프를 통한 시각적 확인
- 평균이 일정한지
- 분산이 일정한지
- 추세나 계절성이 보이는지
- 통계적 가설 검정
- 대표적으로 ADF (Augmented Dickey-Fuller) Test, KPSS Test 등 사용
- ADF Test의 경우, p-value가 0.05보다 작으면 '정상 시계열'로 판단한다
ACF로 확인하는 법
- 비정상 시계열의 경우: ACF가 천천히 감쇠(decay) 함
- 정상 시계열: ACF가 빠르게 사라짐(exponential decay)
즉, ACF가 오래 지속되면 비정상 시계열일 가능성이 높다.
비정상 시계열의 정상화
대부분의 시계열 데이터를 분석하려면 먼저 '정상성'을 만족하도록 변형해야 한다.
이를 정상화(stationarization) 라고 한다.
보통
- 확률 추세를 가진 시계열 -> 차분으로 정상화
- 이분산 시계열 - > 로그 변환 또는 Box-Cox변환으로 분산 안정화
1. 차분 (Differencing)
- 데이터에 추세가 있을 때 주로 사용
- 예:
yt′=yt−yt−1y'_t = y_t - y_{t-1}
2. 변환 (Transformation)
- 분산이 일정하지 않을 때 사용
- 로그 변환이나 Box-Cox 변환으로 분산을 안정화
Reference
Modern time series forecasting with python
'공부기록 > Data Science' 카테고리의 다른 글
| [Alteryx] Input Tools 알터릭스 입력 툴 (0) | 2025.04.06 |
|---|---|
| [Alteryx] 알터릭스란? 설치 방법 부터 데이터 종류까지 (0) | 2025.04.06 |
| [Causal Inference] 1. Introduction To Causality 인과추론이란 | 심슨의 역설 (0) | 2023.12.20 |
| [kaggle] Kaggle API 사용하기 mac (0) | 2022.02.05 |
| 단어 표현 - 어떻게 자연어를 컴퓨터에게 인식시킬 수 있을까 ? (0) | 2022.02.02 |



